by SEAN BRAWLEY
There has been, in recent times, a lot of commentary on the use of metrics in rankings. As institutions across the country start to gear up for the next Excellence in Research for Australia exercise, I confess that I lack the mathematical aptitude to judge whether the current metrics across a range of local and international ranking instruments represent travails into the “quasi-scientific” (Guthrie & Tucker, CMM, March 14). Further, while good on gripe, I have seen few of these recent critiques offering alternatives. One obvious alternative currently lives in some Field of Research Codes (FORCs) in the ERA exercise. That is peer review. Seeing peer review as an acceptable alternative, however, is a pathway down which madness lies.
When the ERA scheme was created, the arts, social sciences and humanities disciplines rejected the sciences’ commitment to metrics and decided that peer review was the best way to judge quality. My observation at the time was that this appeared driven by a distrust of metrics, which the sciences were increasingly using, plus concerns that many of the most important journals in many ASSH disciplines remained cottage industries that sat outside the big publishers and therefore outside citation metrics.
It certainly remains true for me as an historian that citation measurement databases only capture a fraction of my citations. Scopus is hopeless for me. Google Scholar is somewhat better but is probably still not recording much more than half of the citations I have found myself over the years. I used to record in a word file every citation to my work that I came across but after years of doing this found it was not a sustainable method. More recently, Academia.edu has helped and thankfully the ‘S. Brawley’ who seems to get a lot of citations on algae does not contaminate my Google Scholar citations, though I spend more time with my Academia.edu notifications saying, “this is not me” than I do saying “this is me”! I am envious of S. Brawley the scientist! I do know one colleague who has a very enviable H. Index score as recorded by Google Scholar but their score counts a work with significant citations authored by an individual with the same name who writes in a tangential area of interest.
My research portfolio now notes the number of Google scholar citations I have for each output and then includes a long list of some of the more important citations from leading scholars in my field and higher degree research theses that have not been captured by the aforementioned databases. That some of these citations have been found in Google Books continues to leave me perplexed! I also record other data as I find it, such as what libraries of the world hold my books, or the number of downloads of an article. My aim is to try and show, in some measurable form, some sense of my impact.
Returning to ERA, data from the 2018 exercise clearly demonstrates the advantage of being in a metric driven rather than a peer review driven discipline. The chart below (click to expand it) shows a collection of two-digit FORCS and how many institutions improved (above the line) or dropped back (below the line) in 2018 when compared to their 2015 performance.
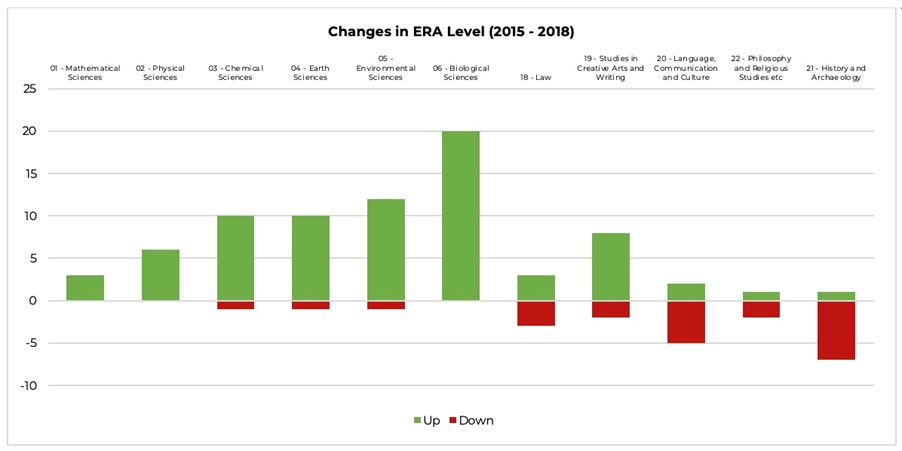
Based on these results I absolutely wish I and my colleagues had reported in a metrics driven FORC!
In leading the preparation of a two digit FORC (21: History and Archaeology) for ERA 2018 at my previous institution, I was quietly confident that our ERA four would convert to an ERA five. My optimism was informed by significant increases in outputs and income, and the fact the books we had submitted for peer review came from even more prestigious publishers with great reviews, and our journal articles were all mostly from Scimago Q1 publications and had been well received. When I pointed out this improvement in our initial draft submission, I was advised by our Research Office, however, that submissions could not allude to past performance. That was disappointing. It was more disappointing when our ERA four returned from the exercise as an ERA three! Why did this happen to us and to so many in the peer reviewed disciplines? To explain it I think the best analogy I can draw is from teaching and learning assessment. What we see in the chart above is what happens when you compare old style gut-feel marking to the curve versus standards-based assessment.
The metrics-driven disciplines essentially have standards through which their College of Experts make data-informed judgements. If the discipline meets the pre-ordained standard it gets what it deserves. They wouldn’t need to note past performance even if they were allowed. In the peer review disciplines, however, we rely on the peer reviewers and the College of Experts having the same idea of what quality looks like (across a diverse range of disciplines) and then the assigning of the final ranking is contested and debated. One result of this approach, it appears, is that even basic arithmetic seems to be set aside. I confess I remain confused, as must many colleagues at a certain Queensland institution where they got a lower two digit score in the 21 FORC in 2018, despite actually improving their sum total of four digit scores in that code. What’s the point of having this basic marking rubric if the results don’t align? Could this happen in a metric driven FORC code? Others will need to tell me.
A decade ago, when I would inform an ASSH colleague I was a fan of the metric approach they often frowned and explained why such approaches could never work for our disciplines. These days, however, the opposite is true. I can’t recall the last time a colleague challenged my opinion — certainly none since the 2018 round which provoked so much negative commentary within the ASSH community and a maelstrom of scuttlebutt about what may or may not have happened within the College of Experts.
Of course, there remain issues with data-driven approaches as have been pointed out by others, but we should not throw the baby out with the bathwater. Given it has been written about and tested for some time, can we be too far away from meaningful semantic analysis of citations that will be able to say I have a high H-Index but most people think my work is crap? Is this more useful than the enormously time-consuming exercise of sending out hundreds and hundreds of samples to peer reviewers to offer their two cents which, in the end, may, or may not, make a jot of difference to the College of Experts as it marks to the curve. It’s certainly a discussion worth having though it’s too late now for us not to endure another round of peer review madness in ERA 2023. One might suggest that the issue will be brought into even greater graphic relief in the upcoming round with changes to ranking scales. Continuing the assessment analogy, are these changes just a form of grade inflation that will have an even greater impact on those disciplines marking to the curve? Time will tell.
Sean Brawley is PVC Strategy and Planning at the University of Wollongong